

by Paweł Kopeć, Grzegorz Rucki, and Jacek Aleksander Gruca
We introduce JaGAN, the first open source Machine Learning research project of Jagan Solutions, a team of developers specialized in Analytics and Data Science. The purpose of JaGAN is to help you automate the process of building a custom image dataset and then using it to train a GAN model to produce auto-generated images. The term "Jagan" is already known to the fans of the Japanese anime and it describes a superpower of an "evil eye". This superpower allows its wielder to perform the attack known as the "Dragon of Darkness Flame", telepathy, telekinesis, and god-like speed. For the purpose of this article we have to limit ourselves to the last superpower, leaving others for further research.
In this article you will learn how to execute GAN training and how to deal with some issues you may experience while using it.
All you need in order to start GAN training with JaGAN is:
- a script from our repo,
- image tags for your dataset, which will be used to create the dataset automatically with Flickr API,
- JSON files specifying the network architecture.
A GAN (a Generative Adversarial Network) is a Deep Neural Network architecture which uses two networks in its simplest variant. The purpose of a GAN is to create a network capable of mimicking the distribution of the data provided as input. GANs have become popular as Generators of photorealistic images (they were more realistic than those created by any of the previous methods). Finally, GANs also provide an interesting effect of morphing characteristic elements from a particular image training dataset.




The architecture of GANs was introduced by Ian Goodfellow et al. in a paperGenerative Adversarial Network
published in 2014 [1].
A GAN network's mechanism is relatively simple and based on game theory. GANs' architecture contains two artificial Neural Networks competing with each other: the Generator (G), and the Discriminator (D).

The input of the Generator is a random vector, most often drawn from uniform distribution, while the output of the Generator is a tensor of the same shape as the samples in the training dataset. In our case it's a tensor of shape (w, h, c), where: w - image width, h - image height, c - number of color channels. There are 3 color channels: red, green and blue, for RGB. The Generator produces images which try to imitate samples from the training set, so they must be of the same size.
The inputs of the Discriminator are real samples from the training dataset and fake images created by the Generator. On the other hand, the output of the Discriminator is a number, which represents whether the input image is real or not.
As mentioned before, both networks compete with each other while in training. While the objective of the Discriminator is to distinguish whether the input image is real or generated, the objective of the Generator is to fool the Discriminator and to create the new images, which are similar to the images from the training dataset. This framework corresponds to a minimax two-player game.
During training both networks are continuously learning using feedback from each other.
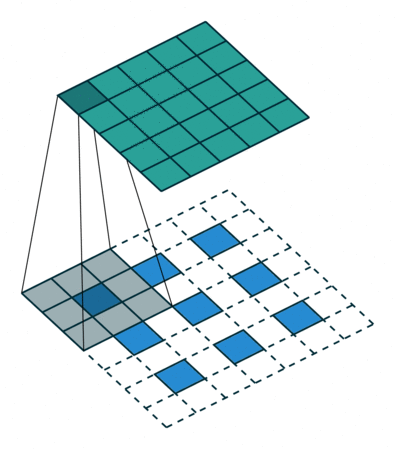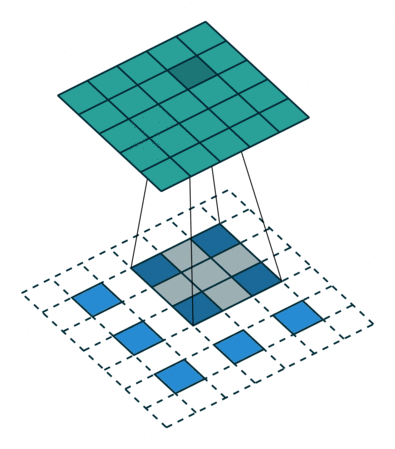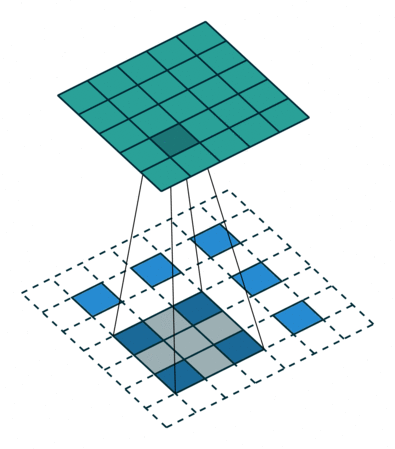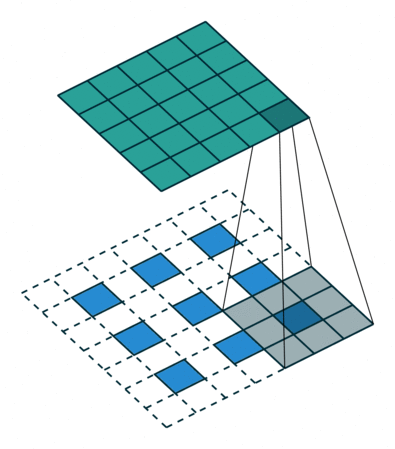
The original GAN architecture proposed in Goodfellow's paper contains two feedforward networks, built only with dense layers. This type of network architecture is called a Multi-Layer Perceptron and currently is rarely used in image processing tasks. The state of the art image processing architectures usually use convolution blocks and thus are named Convolutional Neural Networks (CNNs). CNNs are in a way inspired by the visual cortex in animal brains. Weights adjusted in the training process are grouped in sets called filters. Each filter is used to process several parts of the input image. When compared to a feedforward network, this mechanism allows to reduce the number of parameters needed to train the network.
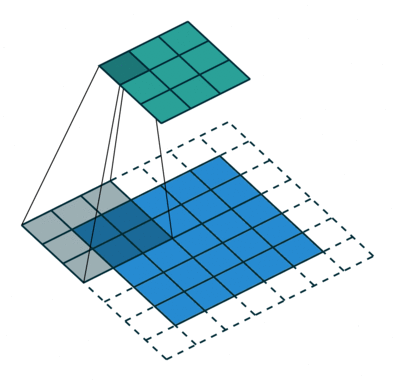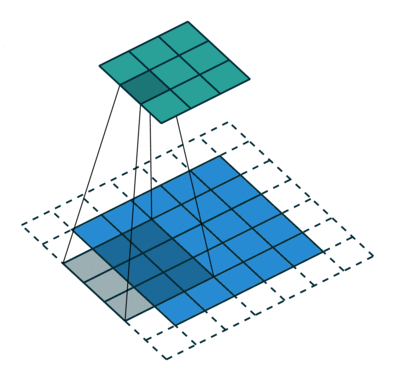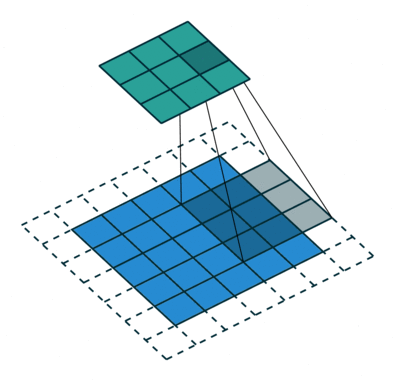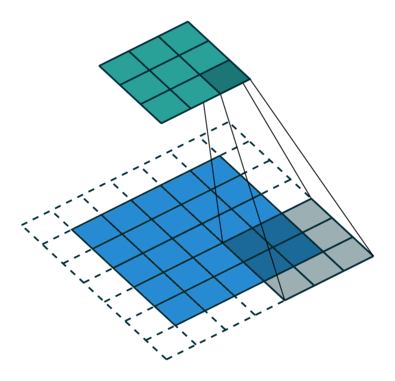
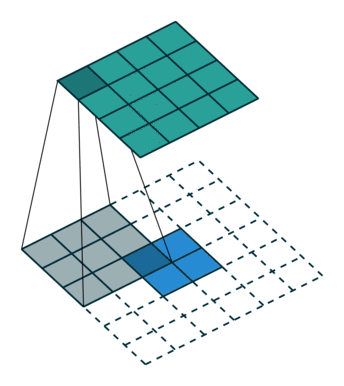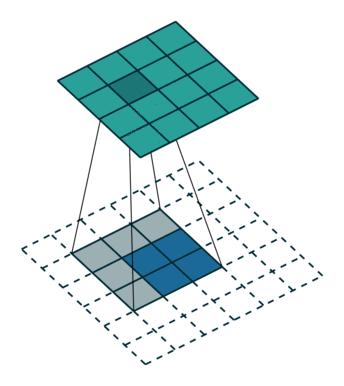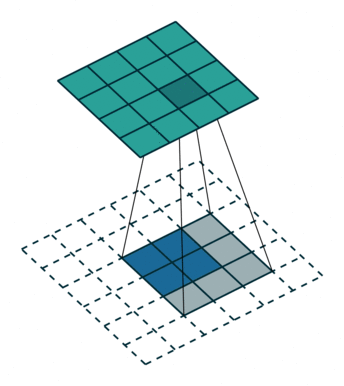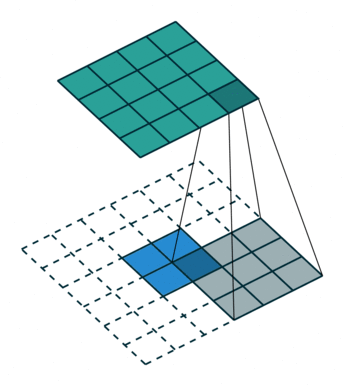
Convolution filters are used for both shrinking and expanding the image. The shrinking operation is called convolution and the expanding operation is called deconvolution.





In order to create GANs using convolutional layers, it is necessary to use both kinds of these operations: convolution in the Discriminator and deconvolution in the Generator.
The use of DCNN (Deep Convolutional Neural Network: a CNN containing multiple convolutional layers) was proposed in the paper Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
[2]. Convolutional layers allow for the generation of much more realistic color images (images generated using architecture proposed in [1] are monochromatic).

A more complex GAN is the conditional GAN. In this case a training dataset is split into a couple of classes (for example animal photos dataset might be split into the rabbit, cat and dog subsets). In the case of conditional GANs, we can enforce that the Generator generates images from a specific class by injecting this class into both networks.
Let us explain how this is achieved. Intermediate results of both the Generator and the Discriminator can be viewed as images. We then append those images with additional channels which represent classes. A channel has the same size as the image, but is filled with ones if a class is used and zeros if it isn't.




Images generated with our best conditional model.Landscapeconditioning classes included Sea, Mountains and Desert.
GANs have evolved rapidly since their first appearance in Goodfellow's paper [1]. There are some commonly known problems and training tips which can improve your GAN's convergence and image quality. Below we list the ones we found most useful when training a baseline model for this tutorial. If you are looking for a more comprehensive source on architecture selection and training process, please refer to a lecture from Facebook AI Research.
One of the first problems we encountered were regular blobs of black pixels. In our normalization formula a black pixel corresponds to a zero-activation value. As a lot of parameters can be negative during the initialization (due to normalization), the deconvolutional layers produce zero activations.

The solution was to simply switch to another non-linear function that does not have this problem. We used Leaky-ReLU which is fairly similar to ReLU and requires a similar number of computations (both Leaky-ReLU and ReLU are composed of linear compartments). As you can see in the two graphs below, Leaky-ReLU does not kill the gradient for negative activations.

Our models converged much faster while using batch normalization, which is a widely used technique for quicker convergence and regularization. Let us stress that for GANs it is extremely important to have separate batch normalization for real and fake images fed to the Discriminator. As verified, mixing those batches resulted in very poor convergence.
The first images we generated had a lot of grid-based artifacts and the further we proceeded with the training, the larger they became. It turned out that those artefacts fit in with the computational characteristics of deconvolutional layers. Those layers are used by the Generator to upsample the noise vector to the image. We discovered that Google also came across the same problem and proposed another upsampling algorithm. Instead of following Google’s lead we decided to upsample the image by cloning each pixel several times. Google's proposal resulted in an algorithm, which is more complex, but it shouldn't discourage you from looking into it.
In Deep Learning research we are usually limited by access to data. To make playing around with GANs a little bit easier we've enabled downloading a custom dataset from Flickr for the preselected image classes. For each class, all you need to do is to specify a bunch of tags used for searching and then let the API download a corresponding number of images. We will now train a sample GAN with images of landscapes downloaded from Flickr.
The below command will download 1000 images from each of the two classes: one defined by tags "desert" and "sun", and the other defined by "sea" and "coast". To download images from Flickr you will need an API key. You can apply for it here.
Execute the following commands to start downloading (use python version as per the README file).
cd src
python3 urls_scraper.py \
--api-key <your-api-key> \
--out-dir jpg \
--tags "desert sun, sea coast" \
--n 1000
You now need to preprocess the images. This includes resizing an image to a square of a desired side length. Preprocessed images will be saved as NumPy arrays consumable by the Neural Network.
python3 preprocess.py \
--in-dir jpg \
--out-dir npy \
--grayscale \ # optional
--max-processes # use this option if you want to optimize your hardware utilization \
--size 64 # side length after preprocessing, 64 by default
Now we can train a basic GAN network. Network architectures are defined in JSON files, so as to make it easier to play around with them.
python3 train.py \
--g-json ../etc/generator.json \
--d-json ../etc/discriminator.json \
--dataset-dir npy \
--logs-dir training \
--d-steps 1 --g-steps 1 \
--validation-interval 50 \
--save-interval 100 \
--learning-rate 0.00005 \
--batch-size 32 \
--beta1 0.9
If you want to train a conditioned GAN, which can generate images of a given class, you need to specify it in the network's configuration JSON. Each class will be represented by a separate one-hot channel in the passing image:
{
"input_shape": [64, 64, 3],
"layers": [
…
{
"type": "concat_conditioning" // class channels will be added here
}
...
]
}
You can launch the training as specified in the JSON files. These have to be prepared in advance:
python3 train.py \
--g-json ../etc/cond_generator.json \
--d-json ../etc/cond_discriminator.json \
--dataset-dir npy \
--logs-dir training \
--d-steps 1 --g-steps 1 \
--validation-interval 50 \
--save-interval 100 \
--learning-rate 0.00005 \
--batch-size 32 \
--beta1 0.9
You can inspect the generated images at <training-dir>/generated_images/ on your drive. To generate more images, you can try your model out with:
python3 generate_images.py \
--model-path training/models/<generator-h5-file> \
--number 20 \
--show-only
Below are some sample results obtained after 95 epochs of training:

We hope that this article gave you some insight into GANs and how to start working with them. Feel free to contact us if you have any questions or comments.
[1]https://arxiv.org/abs/1406.2661
[2]https://arxiv.org/abs/1511.06434
[3]https://distill.pub/2016/deconv-checkerboard/
[4]https://arxiv.org/pdf/1809.11096.pdf
[5]https://www.eff.org/files/2018/02/20/malicious_ai_report_final.pdf
[6]http://imatge-upc.github.io/telecombcn-2016-dlcv/slides/D4L1-adversarial.pdf
[7]https://www.codeproject.com/Articles/1220276/ReInventing-Neural-Networks
[8]http://deeplearning.net/software/theano/_images/no_padding_no_strides.gif
{kind=link}
[9]https://raw.githubusercontent.com/vdumoulin/conv_arithmetic/master/gif/padding_strides.gif
{kind=link}
{kind=link}
{kind=link}
[12]https://medium.com/jungle-book/towards-data-set-augmentation-with-gans-9dd64e9628e6